

In the ever-evolving world of machine learning, one of the most crucial challenges that practitioners face is the phenomenon of overfitting. Regularization, a powerful technique in the machine learning toolkit, serves as a guiding light in the quest for striking the perfect balance between complexity and generalization. In this comprehensive guide, we delve into the intricacies of regularization and explore its role in preventing overfitting, paving the way for more robust and reliable machine learning models.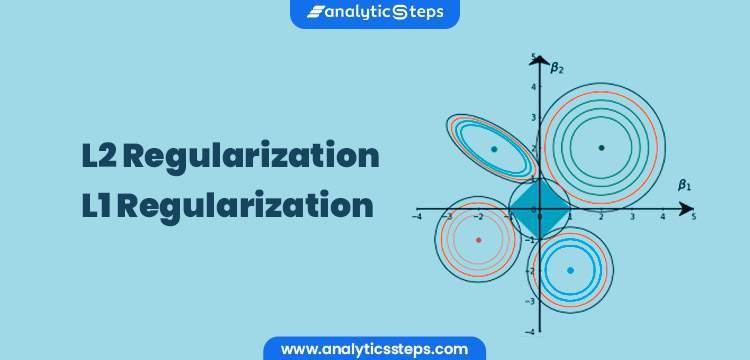

Understanding Regularization Techniques in Machine Learning
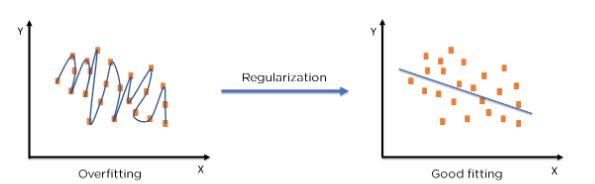
Regularization techniques in machine learning are crucial for preventing overfitting, a common issue that occurs when a model performs well on training data but poorly on unseen data. By adding a regularization term to the loss function, machine learning algorithms can balance the bias-variance trade-off and improve generalization performance.
There are several popular regularization techniques used in machine learning, including L1 regularization (Lasso), L2 regularization (Ridge), and elastic net regularization. Each technique has its own strengths and weaknesses, so it is important to understand how they work and when to use them. By incorporating regularization into your machine learning models, you can prevent overfitting and improve the overall performance of your algorithms.


Common Causes of Overfitting and How Regularization Can Help
Overfitting is a common problem in machine learning where a model learns the training data too well, to the point that it performs poorly on unseen data. There are several common causes of overfitting, such as:
- Complexity of the Model: Models with too many parameters can memorize the training data instead of learning the underlying patterns.
- Small Dataset: When the dataset is small, the model may memorize the data instead of generalizing well to new data.
- Noisy Data: Data with a lot of noise or irrelevant features can mislead the model during training.
Regularization is a technique used to prevent overfitting by adding a penalty term to the loss function that discourages overly complex models. There are different types of regularization techniques, such as L1 regularization (Lasso), L2 regularization (Ridge), and Elastic Net regularization. By applying regularization, the model is encouraged to keep the weights of the features small, preventing it from overfitting the training data.

Recommendations for Implementing Regularization in Machine Learning Models
Regularization is a crucial technique in machine learning that helps prevent overfitting and ensures better generalization of models. When implementing regularization in machine learning models, there are several recommendations to keep in mind:
- **Choose the right regularization technique:** Depending on the complexity of the model and the amount of data available, it is essential to select the appropriate regularization technique, such as L1 or L2 regularization, to effectively control the model complexity.
- **Tune the regularization hyperparameter:** The regularization strength plays a significant role in balancing the bias-variance trade-off. It is important to tune the hyperparameter values carefully through techniques like cross-validation to achieve optimal model performance.
- **Feature selection:** Consider feature selection methods to reduce the complexity of the model and improve its interpretability. This can help in achieving better regularization and preventing overfitting.
In addition to these recommendations, it is crucial to monitor the model’s performance during training and validation to ensure that regularization is effectively preventing overfitting. By carefully implementing and tuning regularization techniques, machine learning practitioners can build robust models that generalize well to unseen data.


Choosing the Right Regularization Technique for Your Machine Learning Project
When it comes to tackling overfitting in machine learning models, choosing the right regularization technique is crucial. Regularization methods help prevent models from memorizing the training data too well, resulting in poor generalization to new, unseen data. In this guide, we will explore different regularization techniques and how to select the most suitable one for your machine learning project.
Some popular regularization techniques include:
- L1 Regularization (Lasso): Adds a penalty proportional to the absolute value of the coefficients, encouraging sparsity in the model.
- L2 Regularization (Ridge): Adds a penalty proportional to the square of the coefficients, preventing weights from becoming too large.
- Elastic Net Regularization: Combines L1 and L2 regularization to leverage the benefits of both techniques.
In Conclusion
regularization is a powerful tool in the world of machine learning, helping to prevent overfitting and improve the generalization of models. By understanding the different types of regularization techniques and how to implement them effectively, we can ensure that our models are robust and accurate. So, the next time you’re training a machine learning model, don’t forget to consider regularization as a key step in your workflow. Happy modeling!






{kind=link}