

In the ever-evolving world of artificial intelligence, machine learning algorithms play a crucial role in making sense of vast amounts of data. However, as these algorithms grow increasingly sophisticated, a new challenge has emerged: out-of-distribution machine learning. This phenomenon occurs when models encounter data that differs significantly from what they were trained on, leading to potentially unreliable predictions. In this article, we will delve into the complexities of out-of-distribution machine learning and explore potential solutions to ensure the reliability and robustness of AI systems.

Introduction
Welcome to the world of out-of-distribution machine learning, where we delve into the fascinating realm of data analysis beyond the norm. In traditional machine learning, the focus is often on training models to recognize patterns within a specific dataset. However, in out-of-distribution machine learning, we explore how models can navigate unknown data points and make predictions outside of their training set.
It’s like sending a machine learning model on an adventure into uncharted territories, where it must rely on its adaptive capabilities to make sense of new information. This field opens up a world of possibilities for applications in various industries, from finance to healthcare. By pushing the boundaries of what machine learning can achieve, we are paving the way for innovation and discovery like never before.

Understanding Out-of-Distribution Machine Learning
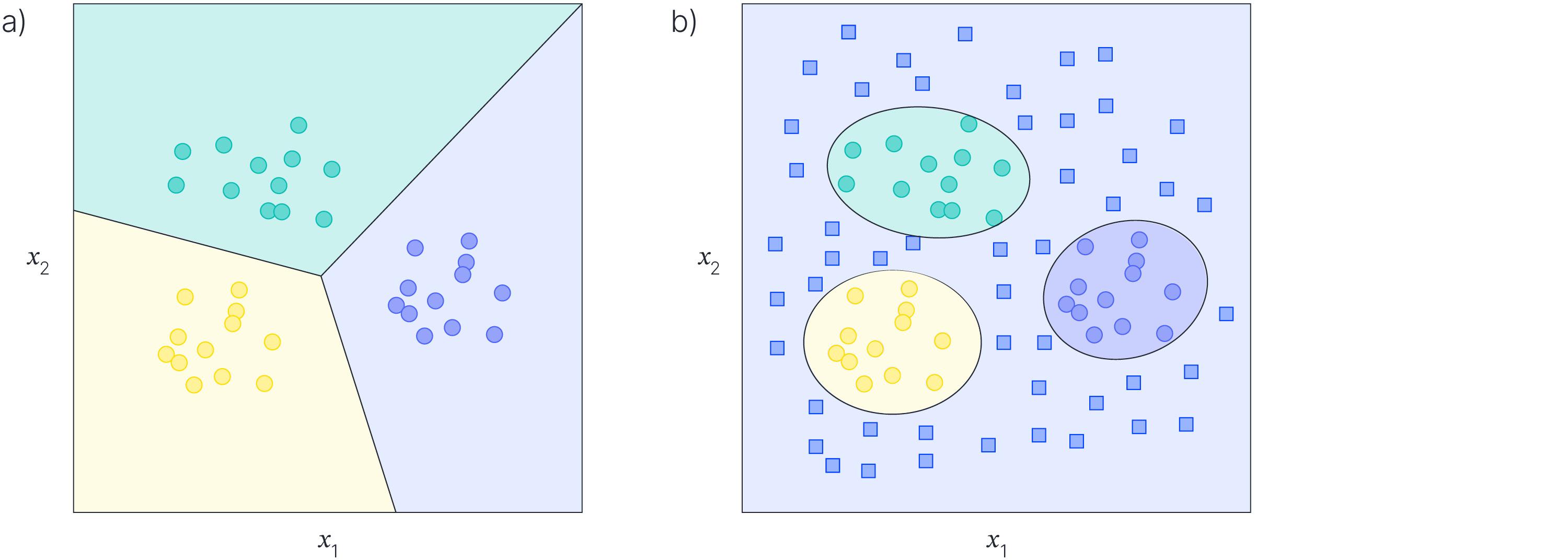
When it comes to machine learning, understanding out-of-distribution scenarios is crucial for building robust and reliable models. In the realm of artificial intelligence, out-of-distribution refers to data points that fall outside the training dataset, leading to unpredictable behavior and potentially incorrect predictions. To tackle this challenge, researchers and practitioners have been exploring innovative approaches and techniques to enhance the generalization capabilities of machine learning models.
One strategy to address out-of-distribution machine learning is through the use of anomaly detection methods. By identifying anomalous data points that deviate significantly from the training data distribution, models can better handle unseen instances during deployment. Additionally, techniques such as uncertainty estimation, ensemble learning, and adversarial training have shown promising results in improving model performance in out-of-distribution scenarios. As the field of machine learning continues to evolve, a deep understanding of out-of-distribution challenges will be essential for creating more resilient AI systems.


Detecting Out-of-Distribution Data
When it comes to machine learning models, is crucial for ensuring the reliability and accuracy of the model’s predictions. Out-of-distribution data refers to data points that are significantly different from the training data that the model was trained on. Detecting and handling such data is essential to prevent the model from making erroneous predictions.
There are various methods and techniques that can be used to detect out-of-distribution data in machine learning models. Some common approaches include using anomaly detection algorithms, calculating uncertainty estimates, and leveraging ensemble methods. By implementing these techniques, machine learning practitioners can improve the robustness and generalization capabilities of their models, ultimately leading to more accurate and trustworthy predictions.


Mitigating Out-of-Distribution Risks
One of the biggest challenges in machine learning is dealing with out-of-distribution risks. This occurs when the model encounters data that is significantly different from what it was trained on, leading to inaccurate predictions and potential errors. To mitigate these risks, it is crucial to implement strategies that improve the model’s ability to handle unknown or unexpected inputs.
One approach is to incorporate uncertainty estimation techniques such as **Monte Carlo Dropout** or **Bayesian Neural Networks**. These methods allow the model to provide a measure of confidence in its predictions, enabling it to recognize when it is facing out-of-distribution data. Additionally, **ensembling** techniques can be used to combine multiple models to make more robust predictions and reduce the impact of outliers. By implementing these strategies, machine learning systems can become more reliable and better equipped to handle a wider range of scenarios.
In Summary
As we delve deeper into the realm of machine learning, the concept of out-of-distribution data becomes all the more relevant. By understanding the challenges and implications of dealing with such data, we can enhance the robustness and reliability of our models. As the field continues to evolve, it is crucial to stay informed and adapt to new methodologies and practices. So let us embrace the possibilities that lie ahead and continue to push the boundaries of what is possible in the world of machine learning.






{kind=link}