In the ever-evolving landscape of artificial intelligence, the quest for models that can seamlessly interpret and classify vast and varied datasets has been relentless. Enter the realm of TabLLM, a groundbreaking approach that marries the prowess of Large Language Models (LLMs) with the intricate world of tabular data. This innovative methodology promises to revolutionize the way we handle and glean insights from tables, a data format as old as data itself yet notoriously challenging for AI to navigate. TabLLM isn’t just another step forward; it’s a leap into a future where few-shot classification of tabular data isn’t just possible but remarkably efficient. Join us as we delve into the intricacies of TabLLM, exploring how it stands to redefine our expectations from AI in managing the structured simplicity and complex potential of tabular data.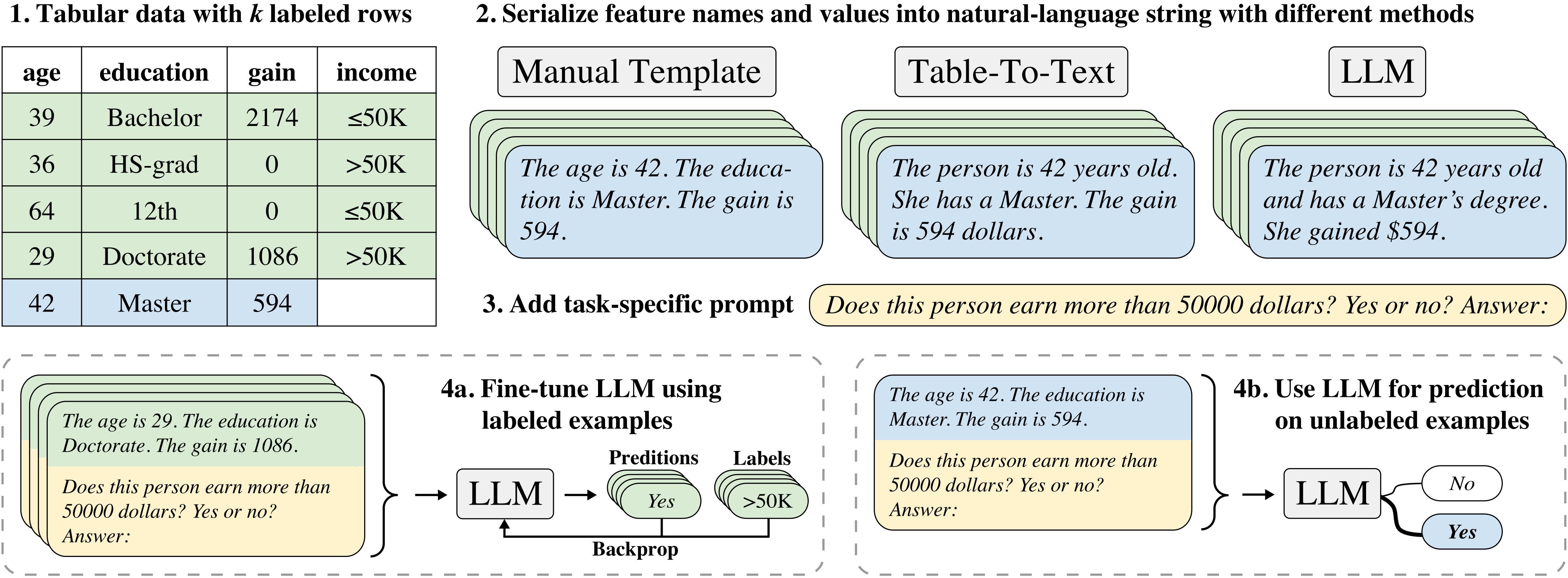
Unlocking the Power of TabLLM for Tabular Data Analysis
In the realm of data science, the advent of TabLLM marks a significant leap towards harnessing the intricate patterns hidden within tabular datasets. This innovative approach leverages the prowess of Large Language Models (LLMs) to perform few-shot classification tasks, a method where the model learns from a minimal number of examples. The beauty of TabLLM lies in its ability to understand and interpret data in a way that mimics human cognitive processes, thereby unlocking new dimensions of data analysis. By treating tabular data as a form of language, TabLLM can efficiently navigate through rows and columns, identifying relationships and insights that were previously obscured or too complex to decode.
The application of TabLLM in real-world scenarios is as diverse as it is impactful. Consider, for instance, the financial sector, where analysts can use TabLLM to predict market trends based on historical data with unprecedented accuracy. Or in healthcare, where TabLLM’s few-shot classification can help in diagnosing diseases by analyzing patient records and lab results, all with minimal input examples. The following table showcases a simplified example of how TabLLM could categorize patient data for disease prediction:
| Patient ID | Age | Symptoms | Predicted Condition |
|---|---|---|---|
| 001 | 30 | Fever, cough | Common Cold |
| 002 | 45 | Fever, weight loss, night sweats | Tuberculosis |
| 003 | 29 | Shortness of breath, chest pain | Asthma |
Boldly stepping into the future, the integration of TabLLM into data analysis workflows promises not only to enhance the precision of predictive models but also to democratize access to advanced data science tools. With its few-shot learning capability, TabLLM paves the way for organizations of all sizes to leverage the power of AI in making informed decisions, without the need for extensive data or computational resources. This paradigm shift in data analysis is set to redefine how we understand and interact with the vast oceans of data that surround us, making the complex web of information not only accessible but also actionable.
Diving Deep into Few-shot Classification with Large Language Models
In the realm of machine learning, the ability to accurately classify data with minimal examples, known as few-shot classification, has been a game-changer, especially when dealing with tabular data. Large Language Models (LLMs) like GPT-3 have paved the way for advancements in this area, but their application to tabular data has often been overlooked. Enter TabLLM, a novel approach that leverages the power of LLMs specifically for the classification of tabular data in a few-shot setting. This technique not only opens new avenues for data analysis but also significantly reduces the time and resources required for model training. By transforming tabular data into a format that LLMs can understand, TabLLM creates a bridge between traditional data types and the cutting-edge capabilities of language models.
The core of TabLLM’s methodology lies in its innovative data preprocessing and encoding strategies. Before feeding the data into the LLM, TabLLM converts the tabular dataset into a series of descriptive texts that encapsulate the essence of the data. This process involves:
- Highlighting key features: Identifying and emphasizing the most relevant columns and rows that contribute to the classification task.
- Summarizing data points: Generating concise summaries for each instance in the dataset, making it easier for the LLM to grasp the context and nuances of the data.
Furthermore, TabLLM employs a dynamic few-shot learning framework that adapts to the complexity and size of the dataset, ensuring optimal performance across various tabular datasets. This approach not only enhances the model’s accuracy but also its versatility, making it suitable for a wide range of applications, from financial forecasting to healthcare diagnostics.
| Feature | Description | Impact on Few-shot Classification |
|---|---|---|
| Preprocessing | Conversion of tabular data into descriptive text | Enables LLMs to understand and classify tabular data efficiently |
| Dynamic Learning Framework | Adapts to dataset complexity | Improves model accuracy and versatility |
| Summarization | Concise representation of data points | Facilitates better understanding and context for LLMs |
By integrating these elements, TabLLM not only showcases the potential of LLMs in handling tabular data but also sets a new standard for few-shot classification tasks. This approach heralds a significant leap forward in making machine learning models more efficient and accessible, especially in scenarios where data is scarce or highly specialized.
Maximizing Efficiency: Tips for Implementing TabLLM in Your Data Projects
Incorporating TabLLM into your data projects can significantly enhance the way you handle tabular data, especially when it comes to few-shot classification tasks. To ensure you’re getting the most out of this innovative approach, start by meticulously preparing your data. This involves cleaning your datasets to remove any inconsistencies or missing values and standardizing the format for seamless integration with TabLLM. Remember, the quality of your input data directly influences the accuracy of your classifications. Moreover, crafting concise prompts that clearly communicate the task at hand to the model is crucial. These prompts should be designed to guide the model in understanding the context of your data, thereby improving its ability to generate relevant and accurate classifications.
To further maximize efficiency, consider the following practical tips:
- Divide and Conquer: Break down large datasets into smaller, manageable chunks. This not only makes the data easier to handle but also allows you to experiment with different classification strategies on subsets of your data, helping you identify the most effective approach more quickly.
- Iterative Refinement: Start with a broad classification task and gradually refine your prompts based on initial results. This iterative process helps in fine-tuning the model’s understanding of your specific requirements, leading to more precise classifications over time.
- Parallel Processing: Leverage the power of parallel processing to run multiple classification tasks simultaneously. This can significantly speed up the analysis process, especially for large datasets, making your project more time-efficient.
- Continuous Learning: Keep the model updated with new data as your project evolves. This continuous learning approach ensures that the model’s classifications remain accurate and relevant, adapting to any changes in data trends or project objectives.
Implementing these strategies requires a thoughtful approach to both your data and how you interact with the TabLLM model. By focusing on data quality, prompt design, and iterative refinement, you can harness the full potential of TabLLM to achieve highly accurate few-shot classifications, transforming the way you manage and interpret tabular data in your projects.
Beyond the Basics: Advanced Strategies for Enhancing TabLLM Performance
Diving deeper into the realm of TabLLM, the few-shot classification of tabular data with large language models opens a new frontier for data scientists and machine learning enthusiasts. To elevate the performance of TabLLM, it’s essential to leverage advanced strategies that go beyond the conventional approaches. One such strategy involves the intricate tuning of hyperparameters, including learning rate, batch size, and the number of training epochs. These parameters can significantly impact the model’s ability to learn from limited examples. Moreover, experimenting with different embeddings to represent tabular data can provide the model with a richer context, enabling more nuanced understanding and classification.
- Data Augmentation: Creatively augmenting your dataset can lead to substantial improvements in model robustness. Techniques such as synthetic data generation or minor perturbations in the data can help the model generalize better from few examples.
- Ensemble Methods: Combining the predictions from multiple TabLLM models can yield a more accurate and stable performance. This approach leverages the strength of diverse models to achieve better generalization on unseen data.
- Advanced Pre-training: Before fine-tuning TabLLM on your specific task, pre-training it on a larger, but similar, dataset can significantly enhance its understanding of the domain-specific nuances in tabular data.
Incorporating these advanced strategies requires a nuanced understanding of both the model’s architecture and the nature of your tabular data. For instance, when adjusting hyperparameters, it’s crucial to monitor the model’s performance on a validation set to avoid overfitting. Similarly, when employing data augmentation, ensuring the synthetic data maintains the integrity of the original dataset’s distribution is key. The table below illustrates a simplified example of how different strategies can impact TabLLM’s performance metrics.
| Strategy | Accuracy Improvement | Notes |
|---|---|---|
| Hyperparameter Tuning | +5% | Varies with dataset complexity |
| Data Augmentation | +3% | Depends on augmentation technique |
| Ensemble Methods | +4% | Improvement through diversity |
| Advanced Pre-training | +6% | Subject to domain relevance |
By thoughtfully applying these strategies, practitioners can push the boundaries of what’s possible with TabLLM, turning few-shot classification challenges into opportunities for groundbreaking insights and performance enhancements.
Insights and Conclusions
As we draw the curtain on our exploration of TabLLM and its innovative approach to few-shot classification of tabular data, we stand at the precipice of a new era in data analysis. The journey through the realms of large language models and their application to the structured world of tables has been nothing short of a revelation. TabLLM, with its ability to decipher and classify tabular data with minimal examples, promises to be a beacon for researchers and practitioners alike, navigating the vast oceans of information with newfound precision and ease.
The implications of this technology stretch far beyond the immediate benefits of efficiency and accuracy. We are witnessing the dawn of an era where the barriers between structured and unstructured data begin to blur, where the language of numbers and the nuance of words converge in harmony. This is not just a step forward in data analysis; it is a leap towards a future where our tools and technologies are more intuitive, more adaptable, and more aligned with the complex tapestry of human knowledge.
As we conclude, let us not forget that the story of TabLLM is still being written. The challenges that lie ahead are as significant as the opportunities. Questions about scalability, accessibility, and ethical use remain open, inviting us to engage in a dialogue that will shape the future of this promising technology. So, as we move forward, let us carry with us the spirit of innovation and inquiry that TabLLM embodies, ready to transform the world of data, one table at a time.
In the end, the journey of TabLLM is not just about the classification of tabular data. It’s about how we, as a society, choose to navigate the ever-expanding universe of information. With tools like TabLLM, we are better equipped than ever to face the challenges of tomorrow, turning data into knowledge, and knowledge into progress. The future of data analysis is here, and it is more exciting than we could have ever imagined.
{kind=link}