In an era where machine learning models are becoming increasingly complex and powerful, understanding their capabilities and limitations is vital for their successful deployment. In a groundbreaking study, researchers have delved deep into the world of large language models, using innovative techniques such as influence functions to shed light on their generalization abilities. Join us as we explore the fascinating intersection of artificial intelligence and linguistics, uncovering the secrets behind these cutting-edge language models.
Introduction to Large Language Models
Large language models have become increasingly popular in natural language processing tasks due to their ability to generate human-like text. However, a key challenge in using these models is understanding how they generalize to different tasks and datasets. Influence functions offer a promising framework for studying model generalization by quantifying the importance of each training example on the model’s predictions.
By applying influence functions to large language models, researchers can gain insights into the behaviors and biases of these models. This approach allows for the identification of influential training examples that may significantly impact the model’s performance on unseen data. Understanding the factors that drive a model’s predictions can lead to improved model interpretability and robustness in real-world applications.

Challenges of Generalization in Language Models
In the world of natural language processing, the are ever-present. These models, while powerful in their ability to generate human-like text, often struggle to generalize well across different types of data or tasks. This lack of generalization can lead to biased or inaccurate results, impacting the performance of the model.
One approach to better understand and improve generalization in language models is through the use of influence functions. By analyzing the influence of individual training examples on the model’s predictions, researchers can gain insight into how the model generalizes to new data. This method allows for the identification of problematic training examples and the development of strategies to improve generalization performance. With the continued advancement of influence functions, we inch closer to creating language models that can truly excel in a wide range of tasks and data types.
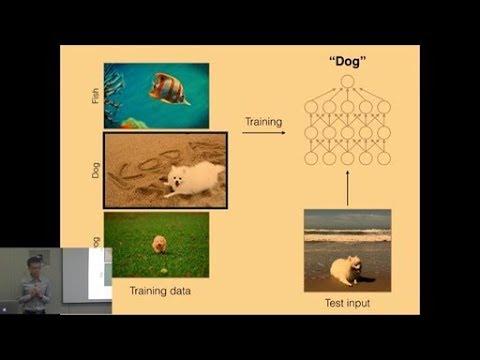
Using Influence Functions for Analysis
When it comes to analyzing the generalization capabilities of large language models, influence functions can be a powerful tool. By examining how individual training data points impact a model’s predictions, we can gain valuable insights into its performance and potential weaknesses. This approach allows researchers to pinpoint specific areas where a model may be overfitting or underperforming, leading to more targeted improvements and optimizations.
One of the key benefits of is the ability to prioritize data points based on their impact on the model. By identifying influential examples, researchers can focus their efforts on understanding and improving the model’s performance on those particular instances. This targeted approach can lead to more efficient model tuning and validation, ultimately resulting in better overall generalization capabilities.

Recommendations for Improving Generalization in Language Models
When it comes to improving generalization in language models, there are several key recommendations that could make a significant impact. Firstly, **diversifying training data** can help expose the model to a wider range of linguistic patterns and contexts, thus enhancing its ability to generalize beyond seen examples. Additionally, **regularizing model complexity** through techniques like dropout or weight decay can prevent overfitting on the training data and encourage the model to learn robust features that generalize well.
Another important recommendation is to **fine-tune the model on domain-specific tasks** to adapt its knowledge and improve generalization within a certain domain. Additionally, **interpreting model predictions** through techniques like saliency maps or attention visualizations can provide insights into the model’s decision-making process and help identify areas where generalization could be improved. By considering these recommendations, researchers and practitioners can work towards developing language models that exhibit strong generalization capabilities across various tasks and datasets.
Concluding Remarks
In conclusion, delving into the fascinating world of studying large language model generalization with influence functions has opened up new avenues for understanding the inner workings of advanced natural language processing systems. By examining the intricate relationship between model predictions and training data, researchers are able to gain valuable insights into the factors that contribute to the generalization capabilities of these models. As we continue to unravel the complexities of language understanding and generation, the use of influence functions promises to shed light on the mysteries that lie at the heart of machine learning. It is through such innovative methodologies that we can push the boundaries of computational linguistics and pave the way for even more remarkable advancements in the field.
{kind=link}